Как мы сократили потребление памяти мониторингом на 75%, мигрируя с Prometheus на VictoriaMetrics Agent в OKD-кластерах
Расскажу про то, как устроен мониторинг в OKD-кластерах, какие у него есть минусы и как мы их побороли, мигрируя основную функциональность на VictoriaMetrics Agent.
Ссылка на статью на хабре – https://habr.com/ru/articles/929226/
Про кластерный мониторинг в OKD
В OKD всё управляется встроенными операторами, и, соответственно, кластерный мониторинг — не исключение. У вас есть openshift-monitoring оператор, который разворачивает всё, что касается мониторинга: prometheus-operator, kube-state-metrics, openshift-state-metrics, node-exporter и так далее. А так как он всё это разворачивает, то он же и обновляет, и вносит изменения в конфигурацию всех компонентов. По обновлению, я думаю, всё понятно — обновляется версия кластера = обновляется версия оператора = обновляются компоненты, которыми оператор управляет. Это в принципе очень удобно. Теперь про конфигурацию: все изменения в компоненты вносятся исключительно через оператор, вы не можете в обход него пойти и что-то там подправить в прометеусе — ваши изменения просто перезатрёт. На словах это очень круто и логично звучит, но реализация... Ниже в разделе "Почему решили переезжать на VMAgent" я подробнее опишу минусы этого.
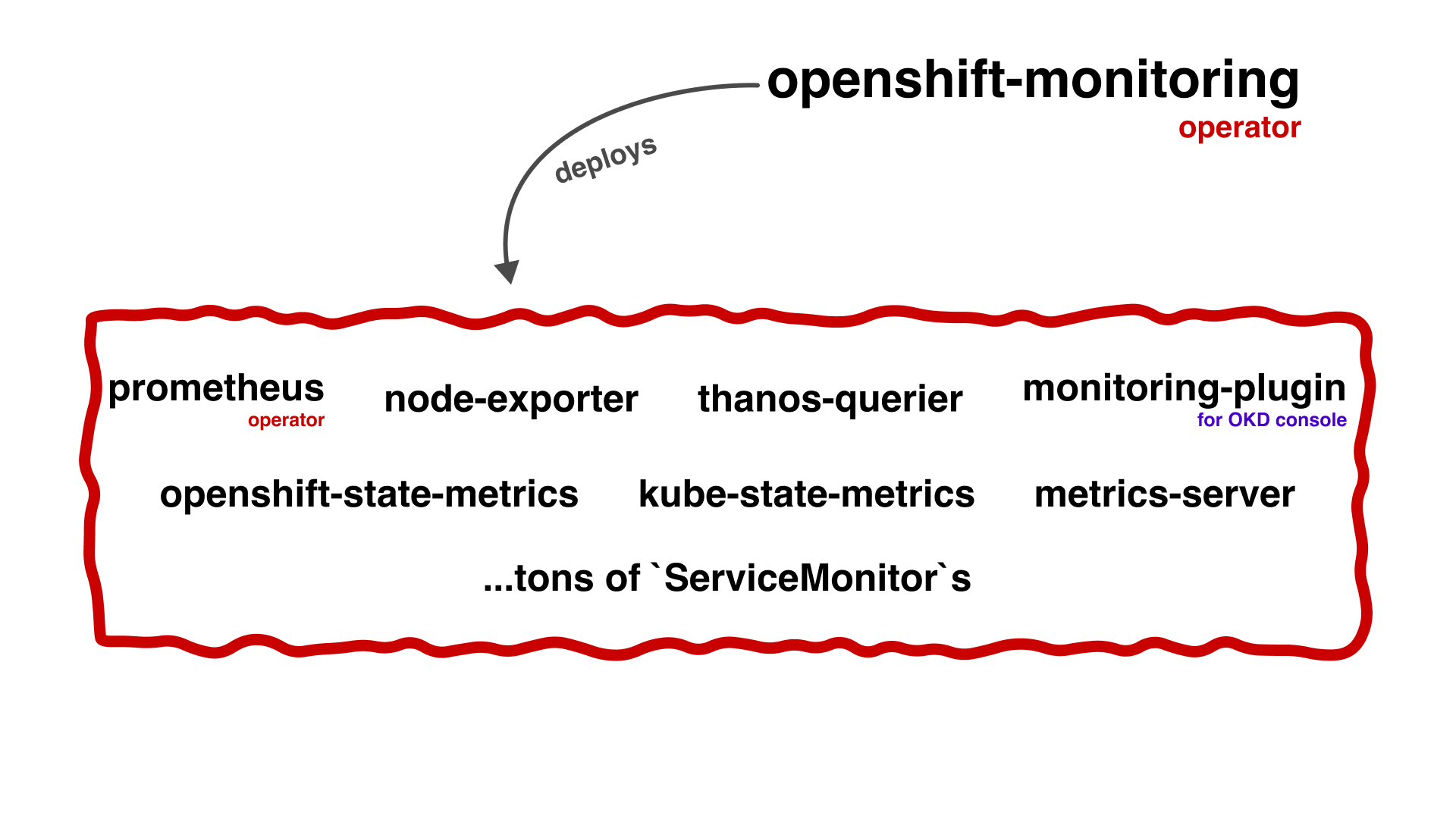
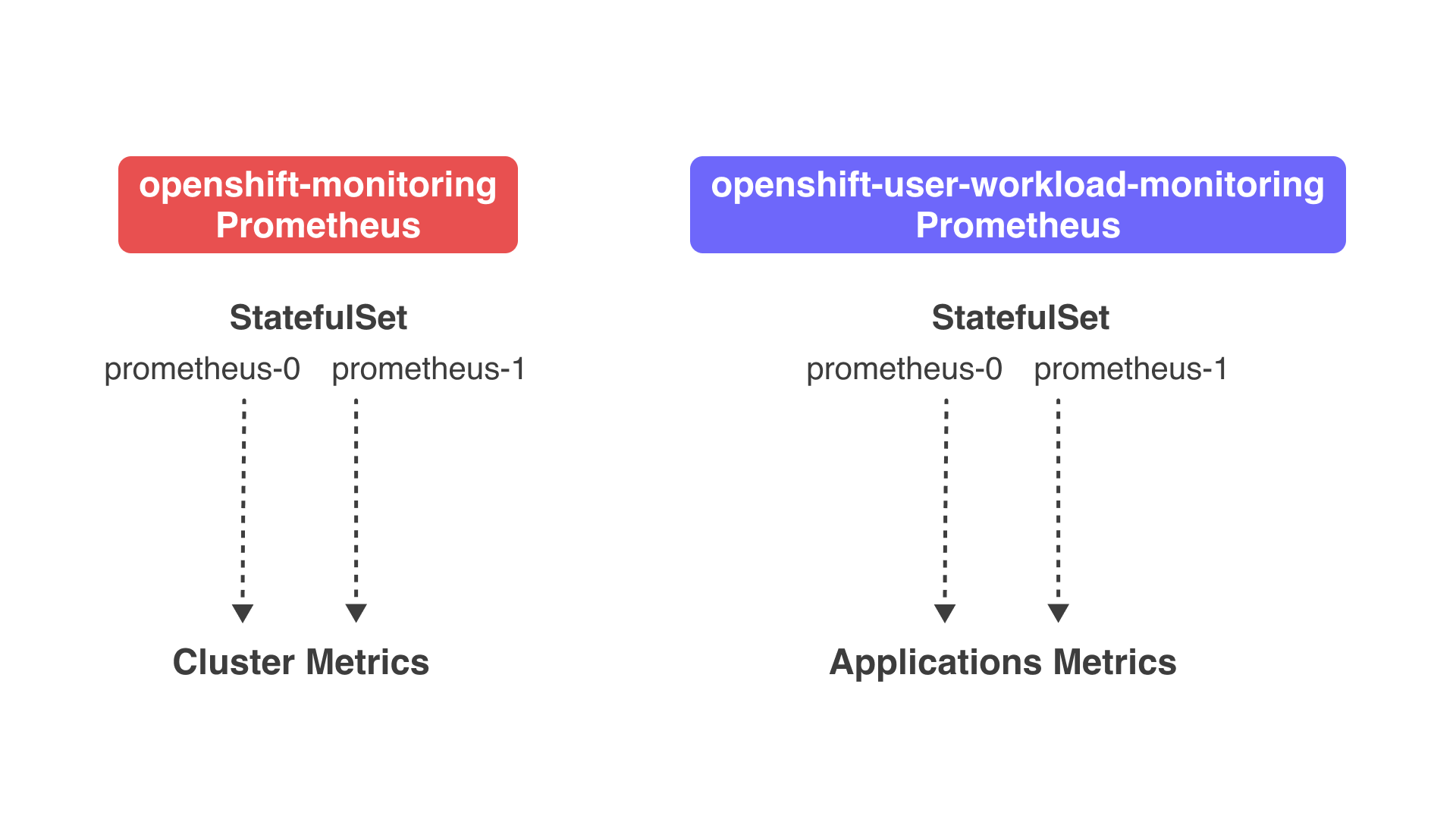
Основную нагрузку в этой схеме у нас принимает Prometheus, так как именно на него и сваливаются все метрики кластера. В OKD есть два типа инсталляций Prometheus: openshift-monitoring (далее по тексту "кластерный прометей") и openshift-user-workload-monitoring (далее по тексту "клиентский прометей"). Первый отвечает за снятие метрик самого кластера, то есть это метрики cAdvisor, node-exporter, kube-state-metrics и так далее. Второй отвечает за снятие метрик с приложений. Это разделение нужно для того, чтобы, например, толстые метрики какого-нибудь пользовательского приложения, убив прометей, не лишили при этом администраторов кластера доступа к "служебным" метрикам.
Развёртка этих двух прометеев в самом кластере — это деплой двух StatefulSet'ов в разных namespace'ах. Количество реплик этих SS не регулируется и в 99% случаев равно двум, подробнее про то, почему количество реплик нельзя регулировать, будет написано ниже в разделе "Почему решили переезжать на VMAgent". При этом сами эти реплики — это идентичные прометеи, которые скрепают в рамках SS одни и те же таргеты. То есть обе реплики кластерного прометея собирают ВСЕ кластерные метрики, а обе реплики клиентского прометея собирают ВСЕ пользовательские метрики :). То есть это не шарды, которые поделили между собой таргеты, и каждый собирает свои.
Как был настроен у нас
Долгое время у нас была реализована следующая схема: есть "коммунальные" кластера VictoriaMetrics, и кластера OKD. В OKD кластерах были развёрнуты кластерный �и клиентские инсталляции прометея. Обе эти инсталляции взаимодействовали с кластером VictoriaMetrics через компонент VMAuth, передавая свои метрики. Также у нас в каждом кластере была и есть OKD Console (веб-консоль кластера), которая ходит в прометей за кластерными метриками для отображения загруженности подов, метрик нод и так далее.
То есть у нас кластерные прометеусы выполняли две функции: все собранные метрики отправляли в VictoriaMetrics (основная функция) и также накапливали метрики для показа их в OKD Web Console (это касается только openshift-monitoring инсталляции Prometheus).
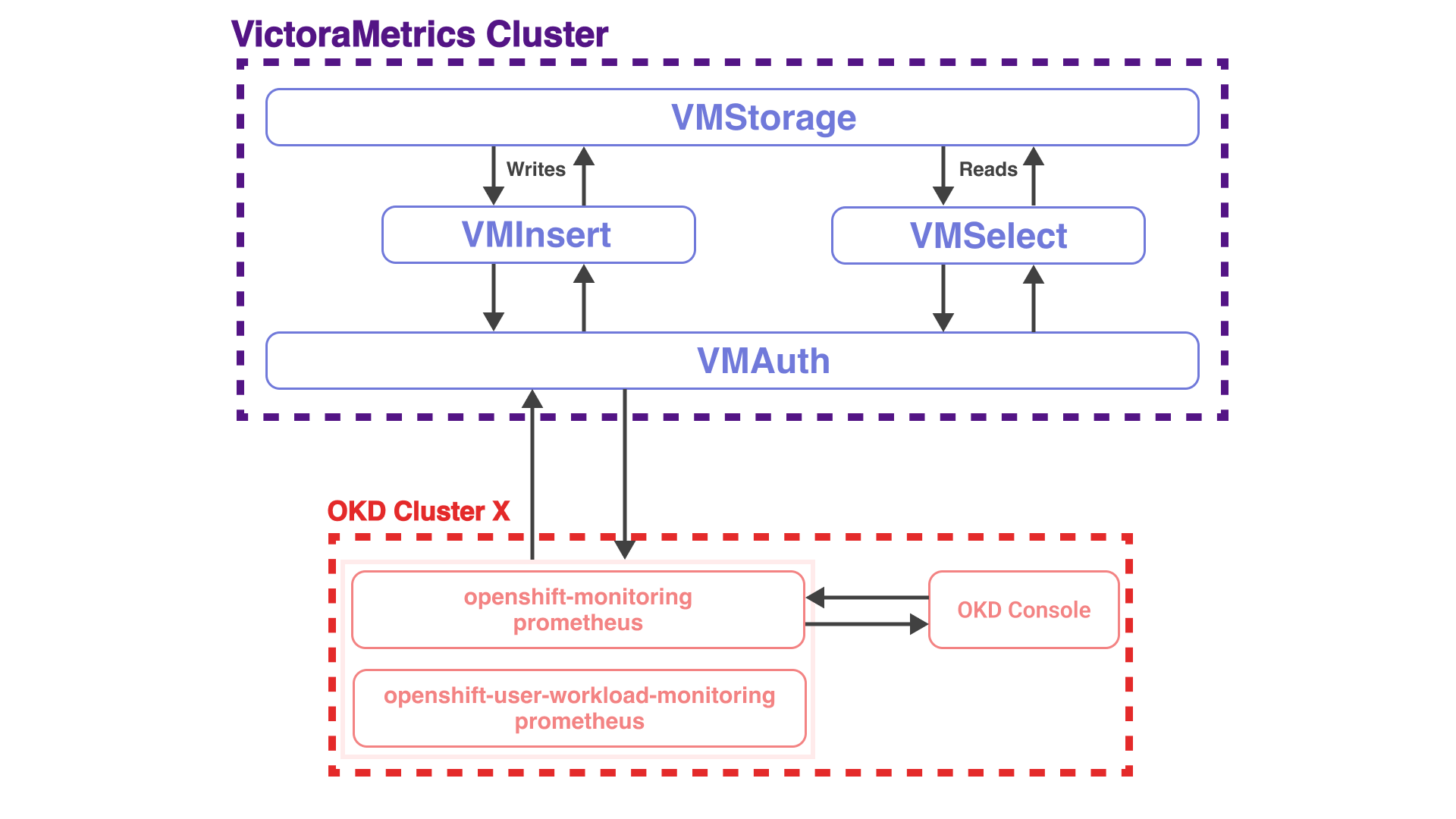
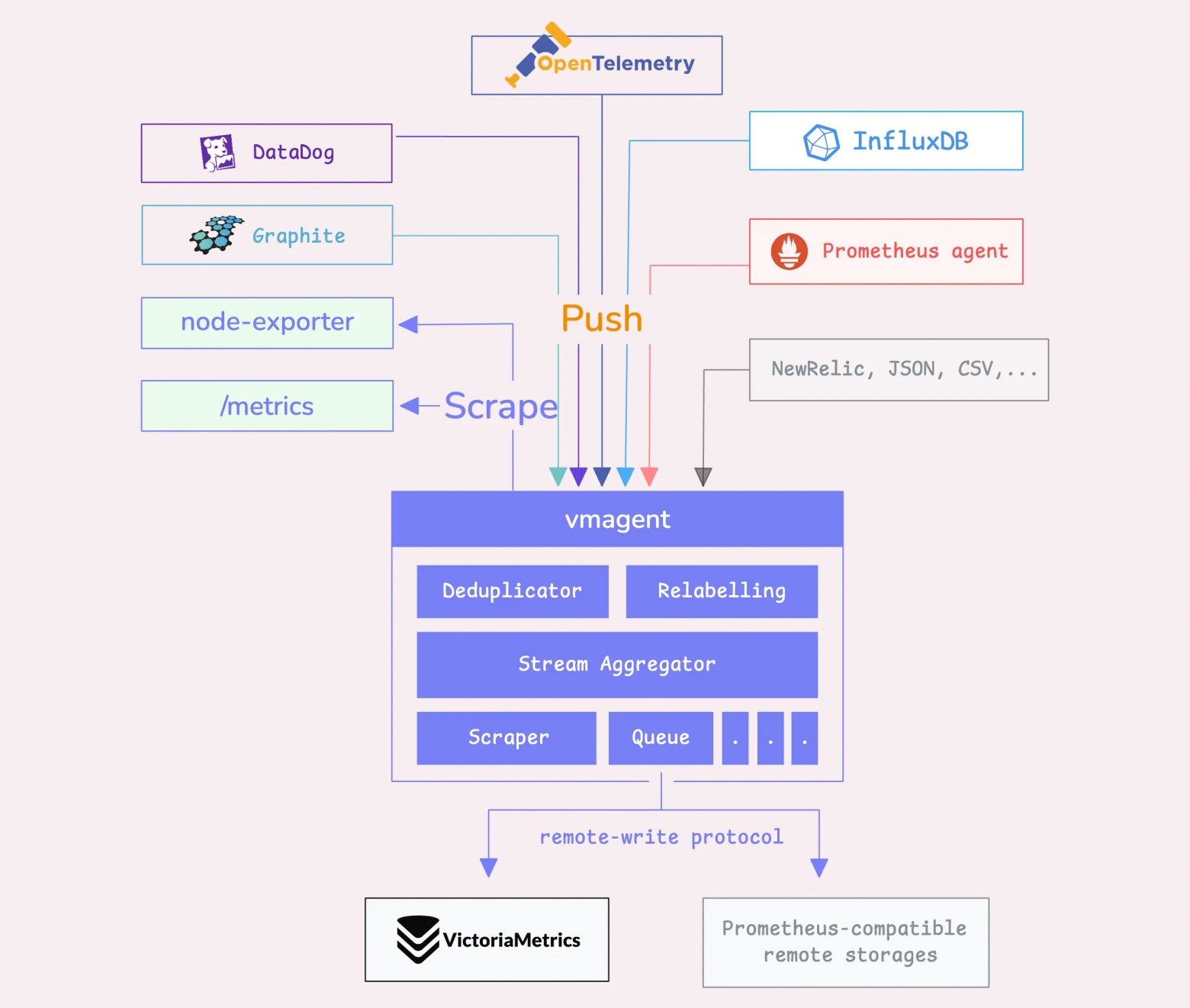
На картинке выше описанная схема представлена чуть более подробнее. На ней видны четыре основных компонента кластера VictoriaMetrics, давайте по каждому вкратце.
- VMAuth: выше я сказал, что в качестве хоста для remoteWrite в прометеусах указывался VMAuth – это компонент кластера VictoriaMetrics, отвечающий за добавление слоя авторизации для нижележащих компонентов. При успешной авторизации он проксирует запрос далее на нужный сервис (VMInsert или VMSelect).
- VMStorage: я думаю, по названию �понятно, что это такое :). Это слой хранения, база данных для всех метрик кластера. Это может одна ВМка или несколько, репликация данных может быть включена, а может и нет, и так далее, возможностей для конфигурации много.
- VMInsert и VMSelect — это, соответственно, пишущий и читающий компоненты. У каждого есть свои специфичные функции, например, у VMSelect'а есть дополнительный кеш для запросов, чтобы лишний раз не ходить в хранилище.
Из представленной схемы кластера VictoriaMetrics, я думаю, уже понятен основной её плюс – гибкая микросервисная архитектура. Это позволяет быстро масштабировать кластер, а также добиваться максимальной отказоустойчивости. Например, "stateless" компоненты (VMAuth, VMInsert, VMSelect) вы можете увезти в Kubernetes, а VMStorage оставить на виртуальных машинах; вы можете отдельно скейлить «write» и «read» части кластера; вы можете выделить отдельные VMSelect для часто "читающего" сервиса, чтобы он не "зааффектил" остальных и так далее.
Что такое VMAgent
VMAgent по сути тот же самый Prometheus за одним исключением — вы не можете запрашивать метрики у VMAgent, потому что он на это не рассчитан. Он накапливает небольшое количество собранных им метрик и сразу отправляет в хранилище, которое поддерживает "Prometheus remote write" или "VictoriaMetrics remote write" протоколы.
VictorieMetrics remote write протокол использует намного меньше сетевого трафика, чем аналогичный протокол от команды Prometheus (подробнее можно прочитать тут). VMAgent автоматически определяет, поддерживает ли хранилище протокол от VictoriaMetrics, и использует его для передачи данных.
Почему решили переезжать на VMAgent
Поговорим наконец, почему мы решили "съезжать" с Прометеуса в наших OKD-кластерах. На самом деле, мигрировали мы не полностью. Как я выше писал:
То есть у нас кластерные прометеусы выполняли две функции: все собранные метрики отправляли в VictoriaMetrics (основная функция) и также накапливали метрики для показа их в OKD Web Console (это касается только openshift-monitoring инсталляции Prometheus).
И вот если основную функцию мы ещё можем забрать у преметея и унести на VMAgent, то отображение метрик в web-консоли OKD мы реализовать через VictoriaMetrics, к сожалению, не можем. В консоли всё, что касается метрик, сильно "захардкожено", и работать оно может только с прометеем, находящимся внутри кластера. Но тем не менее функцию отправки кластерных метрик в VictoriaMetrics можно реализовать через VMAgent, и это очень хорошо.
Теперь давайте перейдем к причинам миграции:
-
Урезанные возможности конфигурирования кластерного прометея в OKD. Список возможных настроек кластерных прометеев.
- Вы не можете точечно управлять списком таргетов, которые скрепает прометей, всё, что у вас есть, это поле
collectionProfile, у которого есть два значения, "full" и "minimal", то есть "скрепай вообще всё что можно" и "скрепай только минимально необходимое". Причем эта настройка доступна только с версии 4.19 (самая последняя на момент написания статьи). - Вы не можете изменять количество реплик стейтфулсетов прометеусов. Если у вас кластер в HA-режиме (3 и более мастеров, подробнее тут), то количество реплик в стейтфулсетах кластерного и клиентского прометеев будет равно двум (в ином случае одной), и вы ничего не сможете с этим сделать. У вас просто будут дублироваться прометеи, и в случае, если у вас не маленький кластер (несколько тысяч подов), то одна реплика кластерного прометея может спокойно потреблять 15–20 ГБ оперативной памяти. Это при условии, что прометей отправляет метрики в удаленное хранилище и ещё накапливает их для OKD Web Console.
- Вы не можете вносить изменения в конфигурацию kube-state-metrics, ограничивая количество и список ресурсов, который он выводит в метрики. Если у вас есть ресурс, который, например, очень часто пересоздаётся/обновляется, то это будет генерировать значительное количество метрик, которое вам, может быть, и не нужно. И вы также не можете поднять свою инсталляцию kube-state-metrics, сконфигурировать её как вам нужно и перенаправить прометеусы на неё.
- Вы не можете точечно управлять списком таргетов, которые скрепает прометей, всё, что у вас есть, это поле
-
Высокое потребление ресурсов (в частности, RAM). В предыдущем пункте затронул эту тему.
-
Стабильность. Этот пункт тоже касается ресурсов :). У всех прометеев обязательно стояли лимиты на потребление RAM, но им его вечно не хватало, особенно если кластер резко рос по числу подов или в случае проведения тех работ. Из-за этого прометеи могли в цикле умирать по ООМу и, соответственно, ослеплять мониторинг. Чтобы это "полечить", нужно было тупо повышать им лимит на потребление оперативной памяти, так как давать ему безлимит на потребление RAM (или просто сильно завышать этот лимит) не очень хотелось. Мало ли что у него может заглючить и он съест всю оперативку на ноде.
Процесс миграции
1. Установка оператора VictoriaMetrics
Миграция начинается с установки VictoriaMetrics Operator, через который мы будем разворачивать инсталляции VMAgent. VMAgent можно поставить и без оператора, напрямую. Есть даже helm chart для этого. Но у установки с помощью оператора есть существенные плюсы:
- позволяет разворачивать в кластере не только VMAgent, но и другие компоненты экосистемы VictoriaMetrics, типа VMAuth или VMSelect;
- позволяет шардировать инсталляции VMAgent'а, то есть он может автоматически делить собираемые таргеты между шардами, количество которых вы также можете регулировать (вместе с этим вы можете управлять и количеством реплик шардов).
Установка оператора производится через helm chart, для деплоя в OKD каких-то особенных параметров не требуется. В чарт встроена проверка на то, что вы деплоите �оператор в OpenShift/OKD кластер, и в таком случае в ресурсы чарта вносятся соответствующие изменения.
После установки оператора он автоматически для каждого ресурса ServiceMonitor (SM) создаст VictoriaMetricsServiceScrape (VMSS).
Если у вас в кластере используется ArgoCD, то рекомендуется включать параметр чарта
operator.enable_converter_ownership, чтобы для созданных автоматически ресурсов VMSS вownerReferenceуказывался SM, по которому они были созданы. Иначе ArgoCD может помечать их как "объекты на удаление".
2. Установка инсталляций VMAgent
Нам необходимы две инсталляции VMAgent: для служебных метрик кластера и для метрик с клиентских приложений (по той же причине, по которой в OKD/Openshift существует это деление). Делается это через создание ресурсов с kind VMAgent. Но если просто взять и создать два таких ресурса, то оператор запустит эти две инсталляции, разобьёт на шарды и тд, но "скрепать" они будут одни и те �же таргеты, нам такое не подходит. К счастью для ресурсов VMAgent можно прописывать селекторы для таргетов, ими мы и воспользовались.
VMAgent для клиентских метрик у нас настроен с такими селекторами:
serviceScrapeNamespaceSelector:
matchExpressions:
- operator: DoesNotExist
key: openshift.io/cluster-monitoring # Специальный лейбл на служебных неймспейсах
serviceScrapeSelector:
matchExpressions:
- operator: DoesNotExist
key: vmagent-cluster-metrics # Специальный лейбл для VMSS, предназначенных инсталляции VMAgent собирающей служебные метрики
А VMAgent для кластерных метрик настроен с такими:
serviceScrapeSelector:
matchLabels:
vmagent-cluster-metrics: "true" # Специальный лейбл для VMSS, предназначенных инсталляции VMAgent собирающей служебные метрики
nodeScrapeNamespaceSelector:
matchLabels:
kubernetes.io/metadata.name: openshift-monitoring # Следит за VMNodeScrape только с конкретного namespace
Таким образом у нас каждая инсталляция собирает только те таргеты, которые предназначены ей.
Из интересного ещё устанавливалось вот такое affinity правило для того, чтобы реплики одного и того же шарда по возможности не попадали на одну ноду:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/instance: vmoperator-vmagent
shard-num: '%SHARD_NUM%'
topologyKey: kubernetes.io/hostname
3. Правки кластерных прометеев
Теперь, когда VMAgent'ы установлены, нужно "отключить" прометеи. К сожалению, полностью отключить можно будет только один из них, но что поделать.
Удаляем configmap, включающий клиентский прометей. Выглядит он как-то так:
apiVersion: v1
kind: ConfigMap
metadata:
name: user-wokload-monitoring-config
namespace: openshift-user-workload-monitoring
data:
config.yaml: |
enableUserWorkload: true # <-- включение прометея для клиентских метрик
# ... далее все его настройки
Удаляем поле remoteWrite из configmap "cluster-monitoring-config" в namespace "openshift-monitoring", тем самым отключая отправку метрик в VictoriaMetrics для кластерного прометея.
Проблемы после миграции
Ра�зумеется не могло всё пройти без проблем. По порядку:
Первое: пропажа некоторых лейблов и агрегирующих метрик. По этому пункту основное — это отсутствие лейбла prometheus_replica на всех метриках, собираемых VMAgent'ами. prometheus_replica — это лейбл, вешавшийся на все метрики, отсылаемые в remoteWrite прометеями, и обозначавший, с какой конкретно реплики (prometheus-0 или prometheus-1) пришла метрика. На всех наших бордах в графане была завязка на этот лейбл, поэтому пришлось править их всех :). Так же кластерные прометеи на ходу создавали агрегирующие метрики (Recording rules), и полностью повторить их с переходом на VMAgent у нас не получилось, поэтому ото всех таких метрик (полный список тут) пришлось отказаться.
Второе: не все ServiceMonitor'ы корректно переводились оператором в VMSS. Выше я писал, что VictoriaMetrics оператор автоматически транслирует ресурсы ServiceMonitor в VictoriaMetricsServiceScrape. В общем SM, нацеленные на служебные сервисы (типа etcd, kubelet и тд), он транслировал неправильно, все их приходилось ручками переделывать.
Результаты
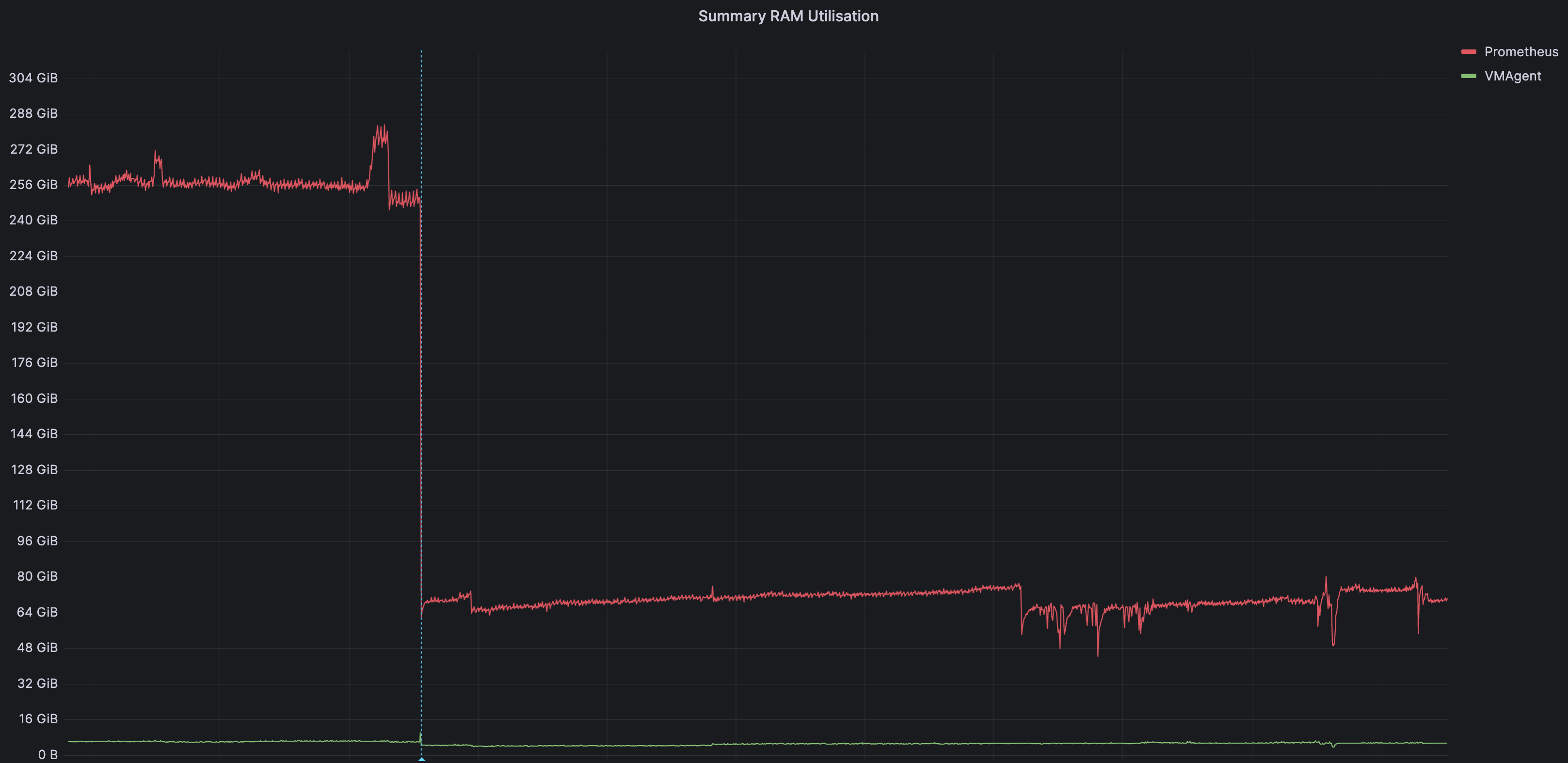
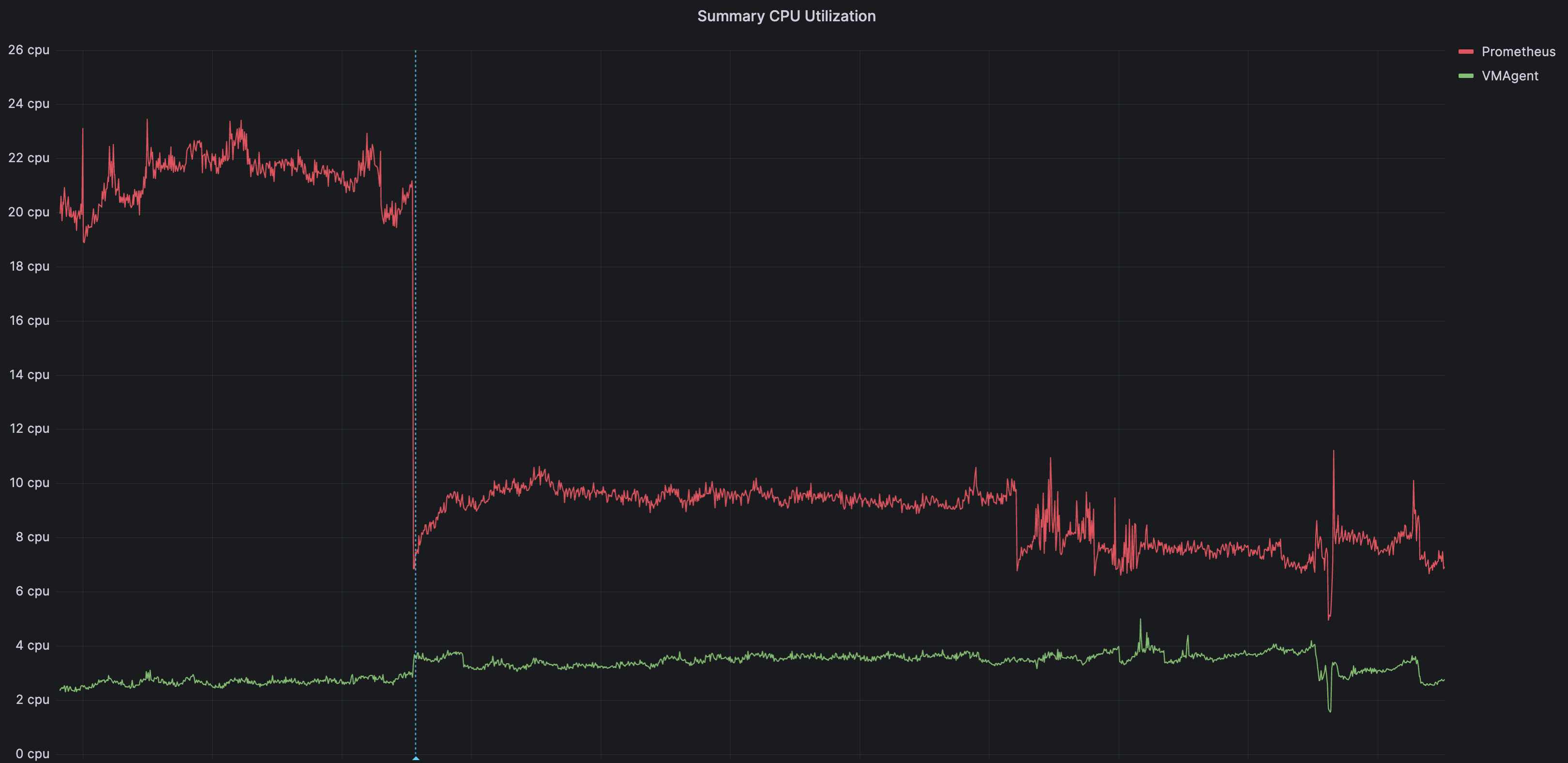
После миграции у нас существенно снизилось потребление ресурсов у компонентов кластеров, отвечающих за мониторинг.
К сожалению, у нас сохранились только метрики, на которых видно отключение remoteWrite у инсталляции кластерного прометея, а также установку VMAgent'ов, которые теперь будут слать метрики в кластер VictoriaMetrics. Этот момент выделен голубой линией на графиках.
Отключение клиентского прометея мы совершили сильно раньше, поэтому метрик за этот период у нас не сохранилось :(. Потреблял он около 10-15% от того, что потребляет кластерный прометей.
- Общее потребление памяти по нашим кластерам
- Общее потребление CPU по нашим кластерам
- Потребление отдельных VMAgent'ов на одном из самых нагруженных кластеров
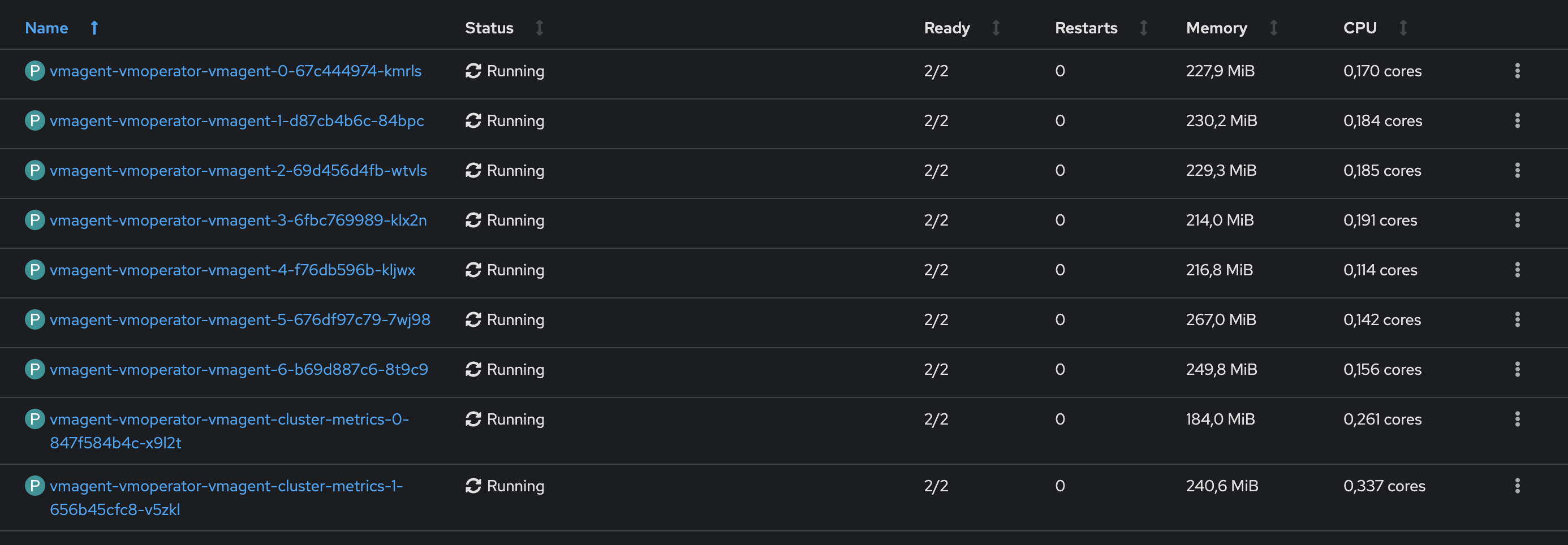
При том, что в целом общие показатели потребления сильно снизились, мы также заметили, что потребление отдельных VMAgent'ов не особо растет при резком увеличении количества метрик, которые они обрабатывают. Пока что за всё время, что у нас работают VMAgent'ы (чуть больше полугода), у нас ни разу не было такого, что они падали от резких скачков нагрузки.