CPU планировщики в Linux
В статье будет рассказано про основные алгоритмы, которые ядро Linux использует для планирования задач, готовых к выполнению. Как влияет приоритет задач и указанная для неё политика на то, как она будет получать процессорное время и сколько.
Сразу хочется оговориться, что помимо описанных ниже алгоритмов и классов планирования в Linux также реализованы дополнительные алгоритмы, основывающиеся на энергопотреблении системы, на cpu capacity и тд. Они встроены в классы, о которых поговорим ниже, но их самих мы затрагивать в рамках этой статьи не будем.
Ссылка на статью на хабре – https://habr.com/ru/articles/807645/
Понятия задачи (task), потока (thread) и процесса (process)
Начнем с базы. Task, thread и process – это, в принципе, достаточно близкие по смыслу понятия, но надо всё-таки разобраться, что каждое из них значит.
Когда вы запускаете приложение, в системе создаётся процесс (process), которому выделяется память на хранение исполняемого кода и других данных. В рамках этого процесса создаётся минимум один поток (thread). Именно среди потоков планировщики Linux и распределяют время процессора, а также решают, в какой очерёдности они будут выполняться. Задачей (task) можно назвать уже непосредственно сами инструкции, которые процессор получает и выполняет. Дальше по статье я буду время от времени называть потоки задачами или процессами, потому что в рамках контекста статьи они своего рода синонимы.
Важно также знать, что у процессов есть поле state, которое, как понятно по названию, показывает, в каком состоянии сейчас находится процесс. Состояний может быть несколько:
- Running или Runnable (R) – процесс в состоянии running прямо сейчас использует процессорное время, в свою очередь runnable процесс только ожидает его.
- Uninterruptible Sleep (D) – процесс ждёт результата операции ввода-вывода. Например, ждёт данные от диска. Такой процесс никак нельзя убить.
- Interruptible Sleep (S) – процесс ждёт какое-то событие и не потребляет процессорного времени. Пример: ввод из командной строки.
- Stopped (T) – процесс получил сигнал
SIGSTOPилиSIGTSTPи остановил свою работу. В этом состоянии процессу можно послать сигналSIGCONTи запустить его снова. - Zombie (Z) – процесс, который получил сигналы на завершение работы, и полностью её завершил – он больше не потребляет ресурсов системы, только PID идентификатор. Он ждет, когда его родительский процесс выполнит системный вызов
wait, после этого Zombie исчезнет. Иногда этого может не происходить, в таком случае приходится дебажить родителя.
Всю информации о процессе можно достать из папки /proc/<PID>, где <PID> – это идентификатор процесса. Если вам нужно получить информацию в более “user friendly” виде, то воспользуйтесь утилитами top, htop, ps и тд.
Политики и классы
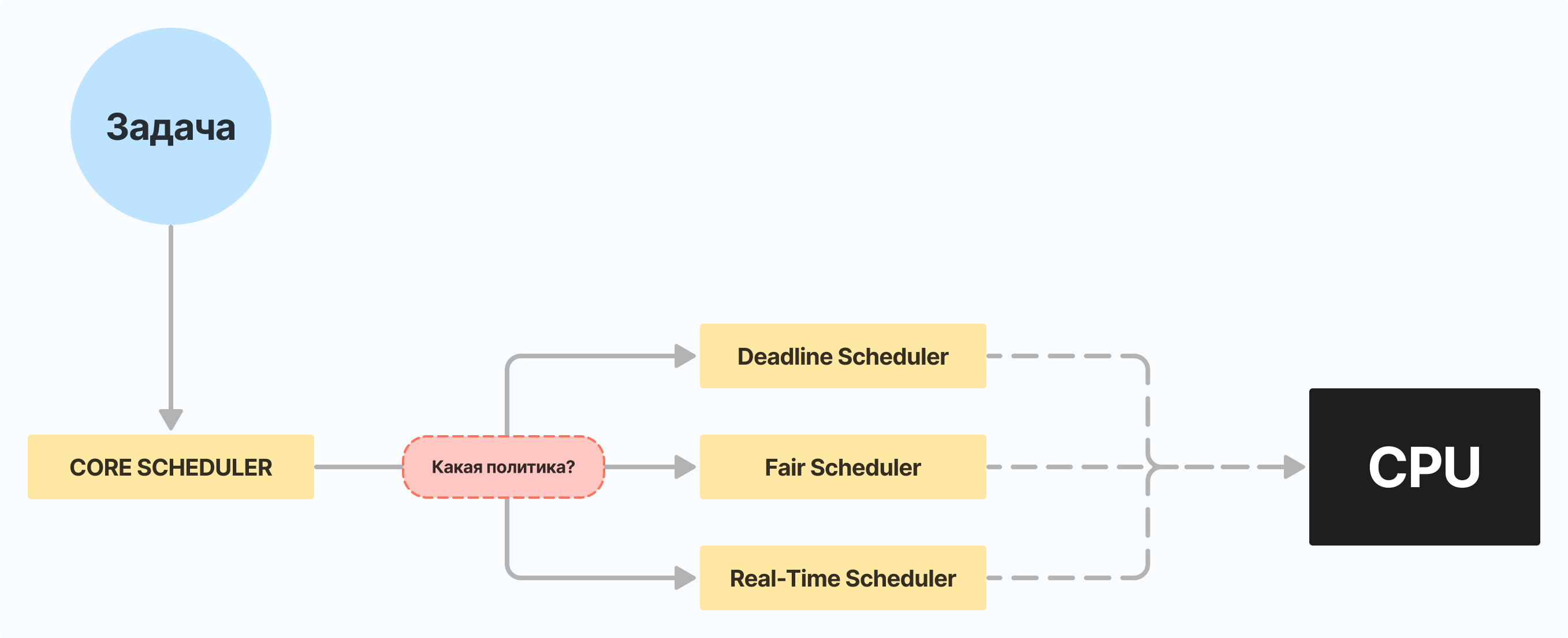
У каждой задачи выставлена какая-то политика, которая определяет, как именно нужно планировать выполнение этой задачи, какие алгоритмы для этого использовать. В свою очередь классы это, по сути, реализации этих политик. Не у каждой политики есть свой личный класс, но все они реализованы в рамках какого либо класса. К примеру, в rt_sched_class реализованы 2 политики: SCHED_FIFO и SCHED_RR, а в dl_sched_class – только SCHED_DEADLINE.
Политика задачи определяется её приоритетом sched_priority, его можно найти в фай�ле /proc/<PID>/schedstat. Сопоставляются приоритеты с классами следующим образом:
sched_priority == 0– класс "Deadline"sched_priority >= 1 && sched_priority <= 99– класс "Real-Time"sched_priority >= 100– класс "Fair"
Класс для “обычных” задач
За распределение процессорного времени для задач с политиками SCHED_OTHER, SCHED_BATCH и SCHED_IDLE отвечает fair_sched_class, описанный в файле kernel/sched/fair.c. В нём с 2007 по 2023 год (с версии 2.6.23 до версии 6.6) использовался алгоритм "Completely Fair Scheduler" CFS, сейчас же это "Earliest Eligible Virtual Deadline First" EEVDF.
У “обычных” задач поле priority игнорируется, вместо него есть NICE, которое играет роль в планировании.
NICE – это показатель толерантности потока к другим потокам :). Чем это значение выше, тем охотнее поток будет делиться процессорным временем или своей очередью (зависит от планировщика, об этом ниже). Минимальное значение -20, максимальное +19.
Про политики:
SCHED_OTHER– Дефолтная политика, используется для абсолютного большинства задач.SCHED_BATCH– Тоже самое, что иSCHED_OTHER, только они не могут “смещать” другие (не SCHED_IDLE), уже запущенные задачи.SCHED_IDLE– Используется для задач с самым низким приоритетом, ещё ниже чемNICE+19. В теории такие задачи запускаются только когда в очереди нет других задач. На практике же может быть и такое, когда IDLE задача выполняется вместе сSCHED_OTHERзадачей, однако при этом получает слишком мало процессорного времени.
"Completely Fair Scheduler” CFS
Как можно понять по имени, основная цель планировщика CFS это максимально “честное” распределение процессорного времени среди всех требующих его процессов. CFS это, как нам говорит документация linux, моделирование “идеального многозадачного CPU”, который, если бы существовал, распределял время процессора примерно так: два runnable процесса, каждый получает по 50% процессорного времени.
В CFS все runnable процессы хранятся в red-black дереве, которое отсортировано по vruntime процесса, что является количеством процессорного времени в наносекундах, которое процесс использовал. Таким образом получается, что в левой части дерева находятся процессы, которые использовали меньше всего времени, а в правой части те, что больше всего. И когда CFS выбирает, какой задаче дать доступ к процессорному времени, он выбирает самую левую задачу в дереве, то-есть ту, которая получила его меньше всех.

Так как любая операция над red-black деревом имеет сложность O(log n), то и сам алгоритм CFS имеет такую же. Однако CFS использует немного модифицированную реализацию этого дерева, которая также хранит указатель на самую левую ноду. Поэтому для поиска процесса с наименьшим vruntime сложность будет O(1).
Когда задача получает доступ к процессорному времени, она получает его на заранее предопределённый промежуток времени, называемый slice. Он может увеличиваться и уменьшаться в зависимости от NICE значения процесса. Таким образом, к примеру, чем меньше значение NICE, тем больше процессорного времени получит задача по сравнению с задачами, имеющими более высокое значение.
Несмотря на то, что CFS действительно хорошо справлялся с “честным” распределением времени процессора на все runnable процессы, у него были и серьёзные недостатки. Один из них это невозможность правильно работать с процессами, которые требуют время процессора, как можно скорее. Для того, чтобы подружить CFS с этой историей были внедрены так называемые latency nice патчи. Они добавляли новое значение latency-nice, которое было зеркально существующему nice значению, в том плане, что тоже имело ограничение от -20 до +19 и его понижение также, как и у nice, понижало толерантность к другим процессам. Если у нового процесса latency-nice был ниже, чем у того, который в текущее время работает в процессоре, то он мог заменить его. Таким образом задачи с низким latency-nice не получали больше процессорного времени, но получали право на его более быстрое выделение.
"Earliest Eligible Virtual Deadline First" EEVDF
Peter Zijlstra посчитал, что для решения той же проблемы, что решают latency-nice патчи для CFS, есть более подходящий путь. Он предположил, что использование алгоритма EEVDF, представленного ещё в 1995 году, может больше подходить для этого и избавит планировщик от кучи «icky heuristics code» (полагаю, что по-русски это значит «говнокод»).
По названию этого алгоритма можно примерно догадаться, как он работает :). Процессору он отдаёт ту задачу, которая “имеет на это право” и у которой раньше всех наступает deadline. В принципе на этом всё. Только осталось разобраться, что вообще значит “имеет право”, и как рассчитывается этот загадочный deadline.
Начнём с параметра “eligible”. Имеет право или не имеет право определяется функцией vruntime_eligible в файле kernel/sched/fair.c, в комментарии к которой написано: “Entity is eligible once it received less service than it ought to have, eg. lag >= 0”. То есть задача “eligible” тогда и только тогда, когда она получила меньше процессорного времени, чем должна. В пример приводится неравенство lag ≥ 0, которое собственно это и значит, потому что lag – это разница между временем, что задача должна была получить, и тем, что она на текущий момент получила. Как это считается? Мы берём средний vruntime всей очереди и отнимаем от него vruntime задачи. Важно понимать, что и средний vruntime очереди и vruntime отдельной задачи у нас считаются, учитывая веса задач, которыми являются их NICE значения. Таким образом, благодаря механизму “eligibility” среди всех процессов “честно” распределяется время.
Теперь перейдём к понятию “deadline”. Deadline – это самое раннее время, до которого задача должна получить slice своего процессорного времени. Считается по формуле: vruntime + (slice / weight), соответственно чем больше вес задачи (зависит от NICE), тем раньше её deadline.
Все runnable процессы так же, как и в CFS хранятся в red-black дереве, однако отсортировано оно не по vruntime, а по deadline’у. Само дерево является “augmented”, то есть дополненным, и содержит в своих узлах не только deadline процесса, но и остальные его данные (в CFS также), в том числе и min_vruntime, который считается по формуле se->min_vruntime = min(se->vruntime, se->{left,right}->min_vruntime). Таким образом появляется возможность фильтровать дерево по “eligibility” и затем уже выбирать самый левый узел, то есть процесс с самым близким deadline’ом.
Класс для Real-Time задач
rt_sched_class, описанный в файле kernel/sched/rt.c, распределяет процессорное время для задач с политиками: SCHED_FIFO, SCHED_RR – обе эти политики описаны в стандарте POSIX. Значение NICE у задач роли не играет, берётся во внимание только приоритет.
SCHED_FIFO (FIFO – First In First Out) берёт задачу с самым большим приоритетом и отдаёт на выполнение в процессор, пока она не заблокируется, не закончит своё выполнение или не будет смещена более приоритетной задачей.
Для SCHED_RR (RR – Round-Robin) справедливо всё то, что и для SCHED_FIFO, за исключением того, что он не позволяет задачам исполняться в процессоре “до победного”, ограничивая время их исполнения. Таким образом, задача, время выполнения которой больше или равно отведённому ей, будет отправлена в конец очереди для задач с таким же приоритетом.
Важно отметить, что так как Real-Time задачи имею больший приоритет, чем обычные, это приводит к тому, что любая новая runnable Real-Time задача смещает обычную running задачу (если такая есть, конечно).
Пользователю, для того, чтобы сделать какую-либу задачу “Real-Time”, нужно воспользоваться утилитой chrt.
chrt -f 10 -p 2445 # Выставляем задаче с PID 2445
# политику SCHED_FIFO и приоритет 10
chrt -r 10 your_command # Выставляем задаче, выполняющей вашу команду,
# политику SCHED_RR и приоритет 10
Класс для Deadline задач
dl_sched_class, описанный в файле kernel/sched/deadline.c, распределяет процессорное время для задач с политикой SCHED_DEADLINE, используя для этого в связке два алгоритма: EDF “Earliest Deadline First” и CBS “Constant Bandwidth Server”. В этом классе у задач игнорируется приоритет и NICE значения, все задачи, благодаря CBS, выполняются “изолировано” друг от друга, то есть не пересекаются.
Deadline задачи имеют самый высокий приоритет среди всех остальных задач в пространстве пользователя. Таким образом, они могут замещать даже Real-Time задачи с самым высоким приоритетом.
В рамках этого класса у задачи есть 3 параметра: runtime определяет сколько процессорного времени задача будет получать, period определяет, за какой период он его получит, и deadline, который рассчитывается с помощью CBS, устанавливает крайнюю отметку времени, до которой задача может выполняться, для того, чтобы она не пересекалась с другими задачами. Алгоритм EDF, в свою очередь, использует значение deadline для понимания того, какую задачу отдавать на выполнение процессору, выбирая всегда процесс с самым ранним deadline’ом.
Чтобы задать процессу “deadline“ политику, пользователю, также, как и в случае с “Real-Time” политиками, нужно воспользоваться утилитой chrt, но теперь ей, помимо приоритета, который всегда 0 для “deadline” задач, необходимо также указать в наносекундах period, runtime и deadline.
# В этом примере задача будет иметь гарантированные 5мс процессорного времени
# с периодом 16.6мс и с дедлайном 10мс
chrt -d --sched-runtime 5000000 --sched-deadline 10000000 \
--sched-period 16666666 0 your_command
Источники
- https://lwn.net/Articles/743740/
- https://lwn.net/Articles/743946/
- https://docs.kernel.org/scheduler/sched-design-CFS.html
- https://docs.kernel.org/scheduler/sched-deadline.html
- https://lwn.net/Articles/925371/
- https://lwn.net/ml/linux-kernel/20230306132521.968182689@infradead.org/
- https://www.cs.unc.edu/~anderson/teach/comp790/papers/posix-rt.pdf
- https://lwn.net/Articles/805317/