Про лимиты на CPU в kubernetes
Поговорим о лимитах на CPU в kubernetes: как работают, какие выставлять, нужны/не нужны и так далее.
Проблема
Мы с нашими клиентами часто сталкивались с ситуацией, когда контейнеру нужно значительно повышать лимиты на CPU, чтобы приложению в нём нормально работало и не теряло в производительности. И под "значительно повышать", я имею ввиду выставлять лимиты, в несколько раз превосходящие реквесты.
Интересное для пользователей/администраторов OpenShift | OKD кластеров
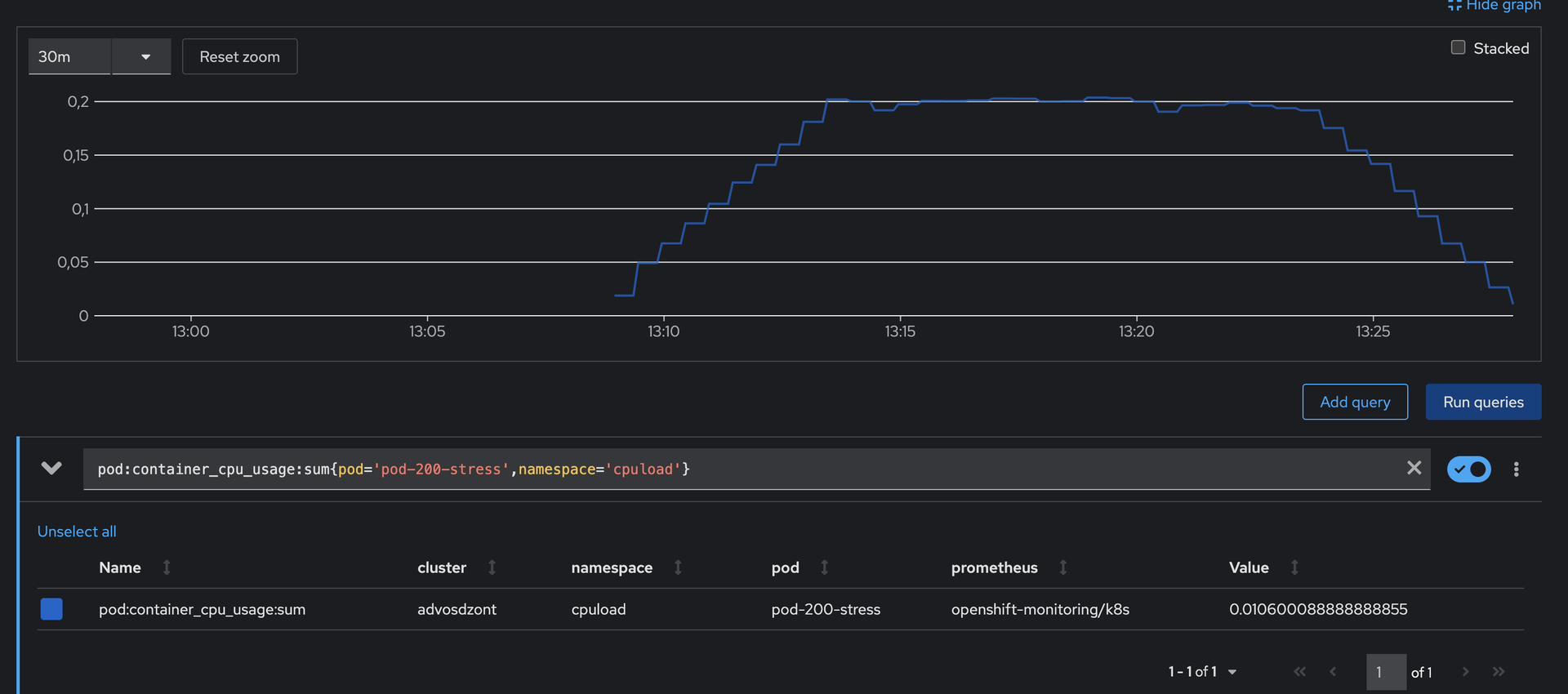
У вас есть приложение в контейнере, которое по графикам потребляет 50m CPU. При том, что лимит у него стоит в 100m, работает оно хреново. На графиках вы не видите, чтобы приложение упиралось в свой лимит по CPU и из-за этого не понимаете, в чем дело. Вы долго думаете, что делать, и решаете повысить лимит в 2 раза. О чудо! Производительность увеличилась в два раза! Но по графикам контейнер продолжает потреблять 50m CPU и не упирается в лимит. Как так?

Это происходит, потому что метрика (pod:container_cpu_usage:sum), которую вам предоставляет OpenShift | OKD, сглаживает резкие скачки и падения потребления CPU. Метрика pod:container_cpu_usage:sum это на самом деле агрегированный через prometheus rule запрос sum(rate(container_cpu_usage_seconds_total{container="",pod!=""}[5m])) BY (pod, namespace).
Ниже на скриншоте приведён пример потребления контейнера, в котором я запускал программу, которая сразу после запуска начинает потреблять все доступные ей ресурсы в рамках одного ядра. Запустил я её в ~13:08 и вместо того, чтобы увидеть максимальное потребление (в нашем случае 0.2CPU) в это время, я вижу, как потребление постепенно растёт, пока не достигает реального значения. Тоже самое происходит и после "убийства" процесса в ~13:23 – вместо того, чтобы моментально упасть до нуля, потребление плавно снижается.
Из-за этого на графиках в консоли OpenShift вы никогда не увидите краткосрочных скачков потребления. Например, если процесс на несколько секунд упрётся в лимит контейнера.
Дробные лимиты на CPU
Причина у нашей проблемы одна – дробные лимиты на CPU. О том, что это такое, как возникает и как лечить – расскажу ниже.
I. У приложения один поток
Давайте представим, что у вас в контейнере запущено приложение, которое под капотом имеет всего один поток. В таком случае, если вы этому контейнеру установите лимит меньше одного ядра, вы будете всегда получать задержки, и соответственно просадки в производительности приложения.

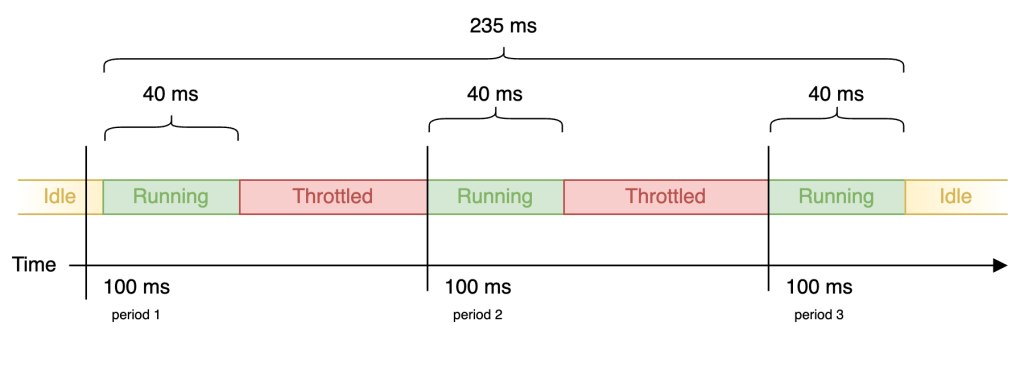
Почему это происходит? Смотрите, когда поток становится исполняемым, то есть подошла его очередь на выполнение в процессоре, оно получает период выполнения, равный 100мс, в рамках которого процесс внутри потока должен выполниться. В случае, если этого не происходит, поток возвращается обратно в очередь и ждет следующего периода. И так он будет получать эти периоды, пока процесс в потоке не завершится.
Длина периода – это настраиваемый параметр. По дефолту – 100мс.
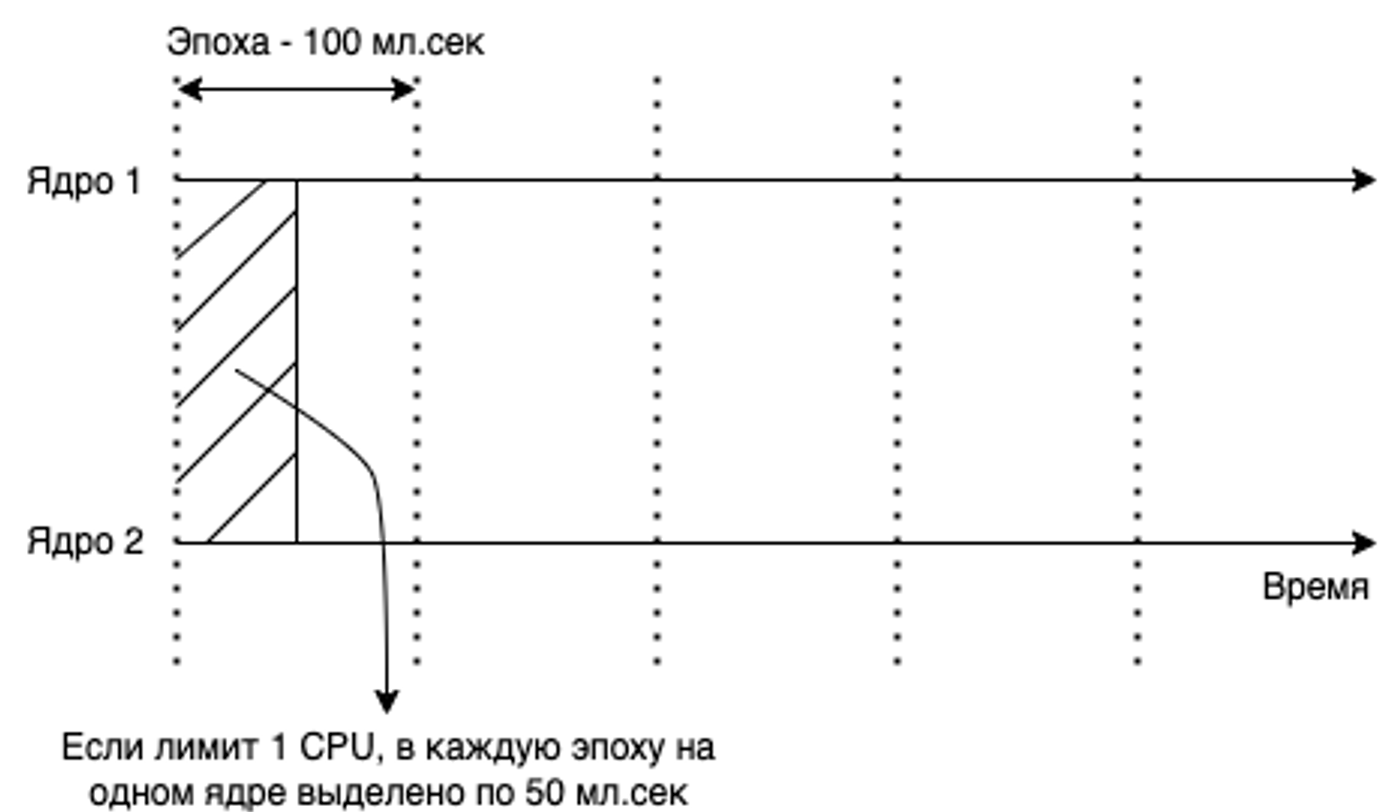
Как работает лимит? Допустим, вы указали контейнеру лимит в 400m. В таком случае поток приложения в контейнере сможет потратить 40мс из 100�мс своих периодов. Что мы после этого получаем? Ниже у меня приведён пример процесса в потоке, контейнеру которого выставлен лимит в 400m CPU. По факту на выполнение этому процессу требуется всего 120мс, но из-за установленного лимита он не может потреблять всё время своих периодов. После того, как он проработал свой максимум (40мс), ему приходится ждать своего следующего периода. Поэтому на картинке мы видим паузы (троттлинг) в работе процесса, из-за которых 120мс превратились в 235мс.
II. У приложения много потоков
Давайте теперь рассмотрим чуть более сложный вариант – когда у приложения несколько потоков. В таком случае лимит, который вы указали для контейнера, будет делиться поровну между активными потоками приложения.
Под "активными" потоками я имею ввиду те, что в данный момент выполняются в процессоре.
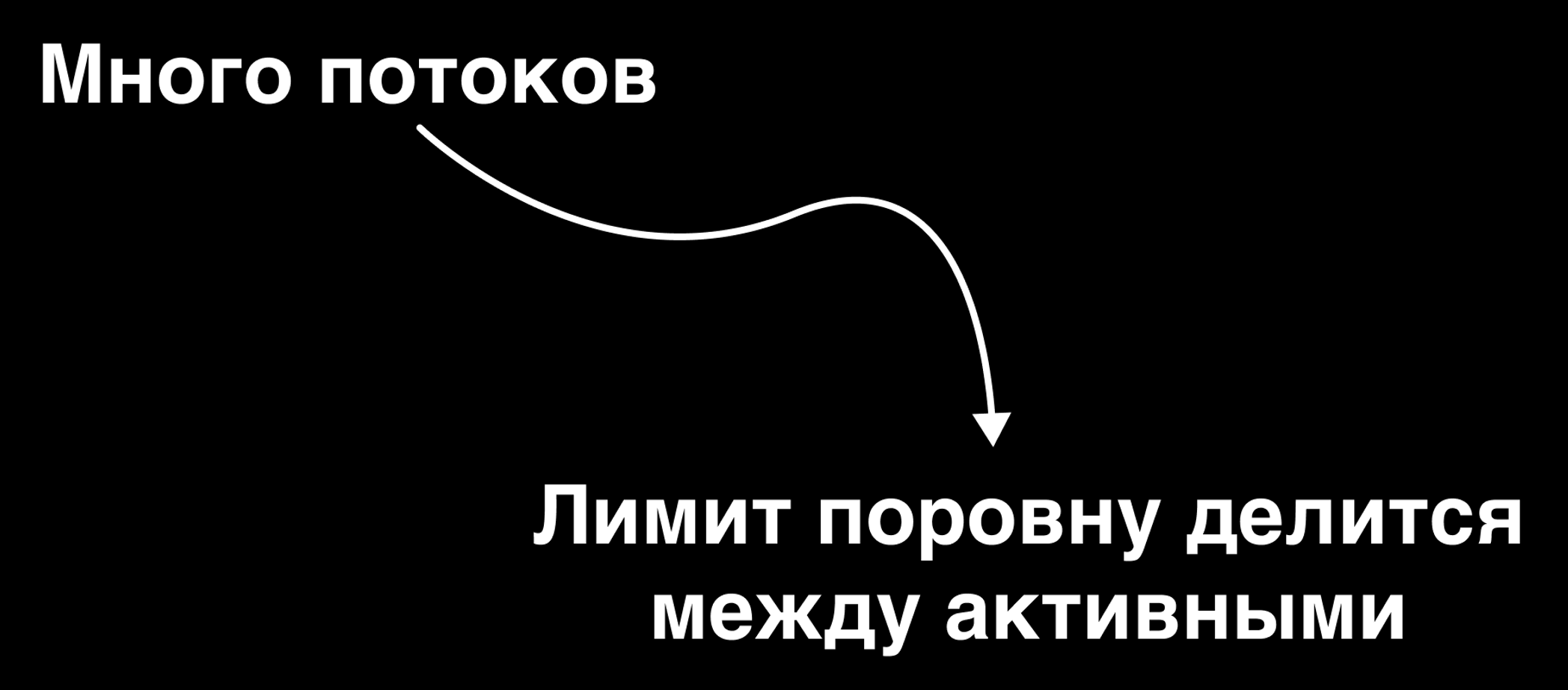
А если у вас лимит делится между активными, то существует большая вероятность того, что каждый из этих активных потоков по итогу получит дробный лимит (меньше одного).

Например, у вас есть приложение с двумя потоками, вы контейнеру этого приложения задаёте лимит в одно ядро. В случае, если работает только один поток, он заберёт себе лимит в одно ядро полностью и соответственно будет иметь доступ к своим 100мс периодам (то есть по сути лимита для него не будет).
В случае же, если будут одновременно работать сразу два потока, то лимит в одно ядро поделится между ними и каждый получит по 500m CPU. А это в свою �очередь означает, что каждый сможет использовать только половину своих периодов, что приведёт к троттлингу.
Итого
Давайте подведём небольшие итоги по дробным лимитам.
- Лимит меньше одного ядра приложений с одним потоком всегда будет приводить к задержкам и, соответственно, к потерям по производительности. Просто потому, что приложение не сможет целиком использовать свой период.
- Для приложений с двумя и более потоками – анализируйте их загруженность. Например, есть приложение с двумя потоками, и эти потоки у него загруженны равномерно. Тут для получения максимальной производительности контейнеру нужно будет задавать лимит в два ядра, чтобы они поровну поделились между потоками и каждый получил по одному целому ядру. В случае же, если из этих двух потоков 90% времени работает только один, а второй выполняет фоновую активность, то контейнеру есть смысл ставить лимит в одно ядро, потому что большую часть времени работает из двух потоков только один.

Отказ от лимитов
Всё, что я рассказал выше про дробные лимиты, это на самом деле просто механизм ограничения использования процессорного времени в linux. Возможно он не учитывает какие-то факторы, которые хотелось бы, чтобы он учитывал, но имеем, что имеем.
Но исходя из того, что было мной рассказано выше – получается, что для максимальной производительности приложенния лимит его контейнеру должен быть либо кол-во потоков = кол-во ядер в лимите, либо кол-во активных потоков = кол-во ядер в лимите. И честно говоря, вторую формулу никто никогда не применяет :). Везде всегда лимит накручивается до максимума, лишь бы избавится от троттлинга. А если так, то зачем он вообще тогда нужен, может отказаться от него?
Идея отказа от лимитов на CPU звучит как ч�то-то сумасшедшее, но на самом деле поизучав статьи в интернете, послушав мнения других пользователей k8s, мы в команде пришли к выводу, что в сообществе давно сформированно мнение о том, что установление CPU лимитов в k8s это своего рода антипаттерн, и что нужно ограничиться только высталвением CPU реквестов.
Но тут сразу возникает вопрос: не получится ли такой ситуации, что у меня на ноде появится процесс, который наплодит себе потоков, сожрёт все процессорное время ноды и не будет давать его другим контейнерам? Ответ: нет, такого не получится. В cgroupV2 существует параметр CPUWeight, который как раз включается в работу, когда на ноде начинается "борьба" за CPU ресурс. Например, у вас есть два потока, оба претендуют на процессорное время. У одного CPUWeight 100, у другого – 400. Тот, у которого 400, будет получать в 4 раза больше процессорного времени относительного того, у которого 100. В свою очередь параметр CPUWeight привязан к CPU реквестам, которые мы устанавливаем нашим контейнерам. Поэтому у нас получается, что в случае 100% загруженности CPU больше процессорного времени будут получать те процессы, которые его больше запросили в своих реквестах.
Но есть один нюанс!Более менее честно процессорное время при "борьбе за ресурсы" будет распределяться только если у контейнеров, между которыми это время распределяется, реквесты хотя бы больше 100m. Иначе будет получаться следующая картина.
(На ноде 16 CPU)
- Пример: два пода со 100% потреблением проц времени. Реквесты: 100m и 1m.




- Пример: два пода со 100% потреблением проц времени. Реквесты: 100m и 20m.




Всё!